
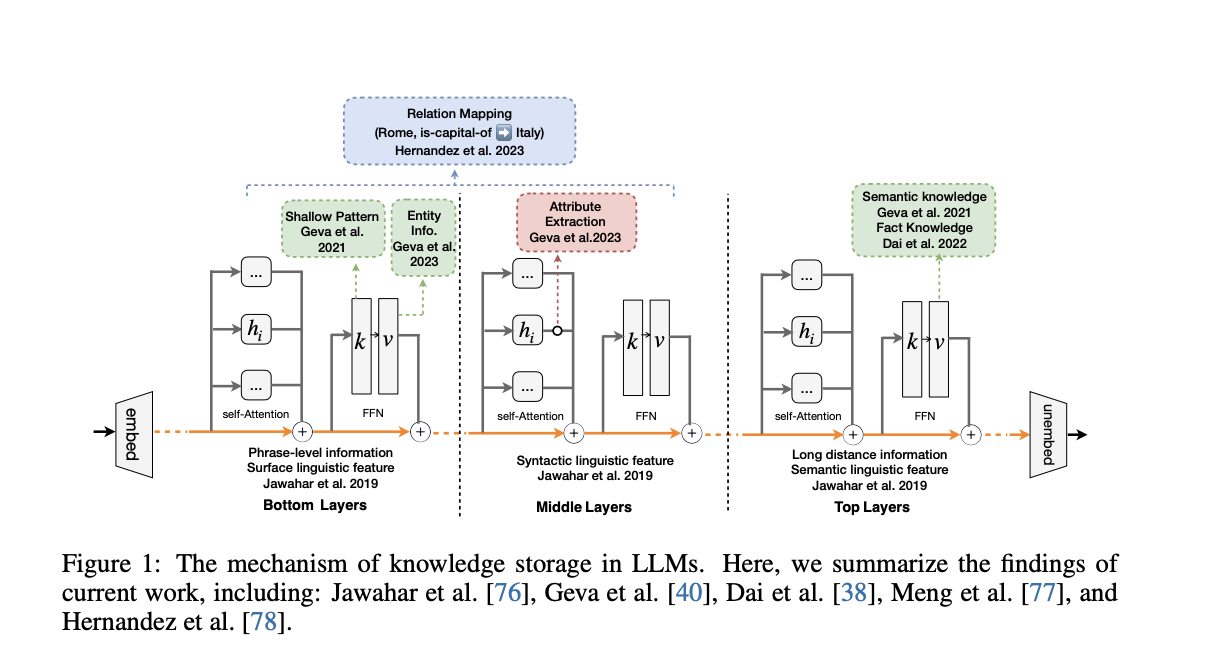
Recently, GPT-4 and other Large Language Models (LLMs) have demonstrated a remarkable ability in Natural Language Processing (NLP) to store vast amounts of information, potentially surpassing human capacity. The success of LLMs in handling extensive data has led to the development of more concise, lucid, and interpretable conceptual methods—a “world model,” so to speak.
LLMs possess the capability to comprehend and navigate intricate geopolitical contexts, offering valuable insights. Previous studies have shown that transformers trained to anticipate future moves in board games like Othello can generate detailed models of the current game state. Researchers have also noted LLMs’ aptitude for grasping images representing sensory and symbolic concepts and tracking topics’ “boolean says within certain circumstances.” With this dual functionality, LLMs serve as valuable knowledge repositories, adept at storing and organizing data in ways akin to human cognitive processes.
Despite their educational benefits, LLMs face constraints such as the potential to generate harmful content, outdated information, and real-world inaccuracies. Addressing these issues through retraining may require significant time and resources. Consequently, there has been a rise in the adoption of LLM-centric information editing techniques to swiftly make targeted adjustments without compromising overall performance. Understanding how LLMs present and process information is vital for ensuring the fairness and safety of Artificial Intelligence (AI) systems. The primary focus of this research is to explore the evolution and status of knowledge processing in LLMs.
A recent study by a collaborative team from Zhejiang University, National University of Singapore, University College of California, Ant Group, and Alibaba Group takes the initial step in presenting an overview of Transformers’ architecture, LLMs’ information handling methods, and related strategies such as parameter-efficient fine-tuning, information augmentation, continual learning, and model generalization. The team lays the groundwork by formally defining the knowledge editing problem and introducing a novel taxonomy that bridges cognitive science and educational theory to offer an impartial perspective on information editing techniques. They classify knowledge editing methods for LLMs into three categories: internal knowledge modification, knowledge incorporation into the model, and utilization of external knowledge.
The researchers outline their criteria for categorization, emphasizing:
- Leveraging Information from External Sources: Analogous to the awareness phase of human cognition, this approach involves assimilating new information within the appropriate context upon initial exposure.
- Embedding Experiential Data Into The Model: Similar to the organization stage in human mental processes, this method draws parallels between incoming data and the model’s existing knowledge. It may involve combining or utilizing a learned information representation instead of the model’s output or intermediary output.
- Updating Intrinsic Information: Resembling the “mastery phase” of acquiring a new skill, this technique entails iteratively integrating information into the model’s parameters through LLM weight adjustments.
The study delves into twelve datasets related to natural language processing, thoroughly evaluating their performance, usability, underlying mechanisms, and other pertinent factors.
Introducing a new benchmark named KnowEdit, the researchers elucidate the experimental results of cutting-edge LLM information editing techniques to offer a comprehensive assessment and showcase the efficacy of these methods in scenarios involving data insertion, modification, and deletion.
The research outcomes highlight how knowledge editing impacts both fundamental tasks and multi-task knowledge editors, indicating that current techniques effectively update information without significantly affecting the model’s cognitive abilities and adaptability across diverse knowledge domains. The researchers observe a notable concentration on one or more value layer columns in modified LLMs, suggesting that LLMs may retrieve insights through a multi-step reasoning process or by referencing their pre-training corpus.
The findings suggest that knowledge localization techniques, such as direct analysis, focus on specific aspects of the queried entity rather than the broader contextual background. The team also explores the potential unforeseen consequences of information editing for LLMs, underscoring its critical implications.
Lastly, the researchers explore a wide array of applications for knowledge processing and assess its potential from various perspectives, including robust AI, efficient machine learning, AI-generated content (AIGC), and personalized agents in human-computer interaction. With a focus on efficacy and innovation, the study aims to pave the way for further research into LLMs. To foster and encourage additional investigations, the researchers have made all their resources publicly accessible, including codes, data splits, and trained model checkpoints.




