In the realm of conceptual models, particularly in the domain of image generation, diffusion models play a pivotal role, undergoing significant transformations. These models have gained prominence in fields like computer vision by effectively converting sound into structured data, notably images, through denoising techniques. They have become a cornerstone of technological progress in artificial intelligence and machine learning, showcasing their prowess in converting raw noise into intricate visual representations.
A major challenge that persists with these models is the subpar quality of the images they produce in their raw state. Despite advancements in the architectural concepts, the generated images often lack realism. This issue primarily stems from the heavy reliance on classifier-free guidance, which aims to enhance sample quality by training the diffusion model in both a provisional and absolute manner. However, the limitations and hyperparameter sensitivity associated with this guidance, such as issues of overexposure and oversaturation, tend to detract from the overall image quality.
Researchers at ByteDance Inc. have introduced a novel approach that integrates perceptual loss into diffusion training. They ingeniously leverage the diffusion model itself as a visual network, leading to significant improvements in sample quality through enhanced sensory loss. By diverging from conventional methodologies, this innovative approach offers a more sophisticated and intrinsic way of training diffusion models.
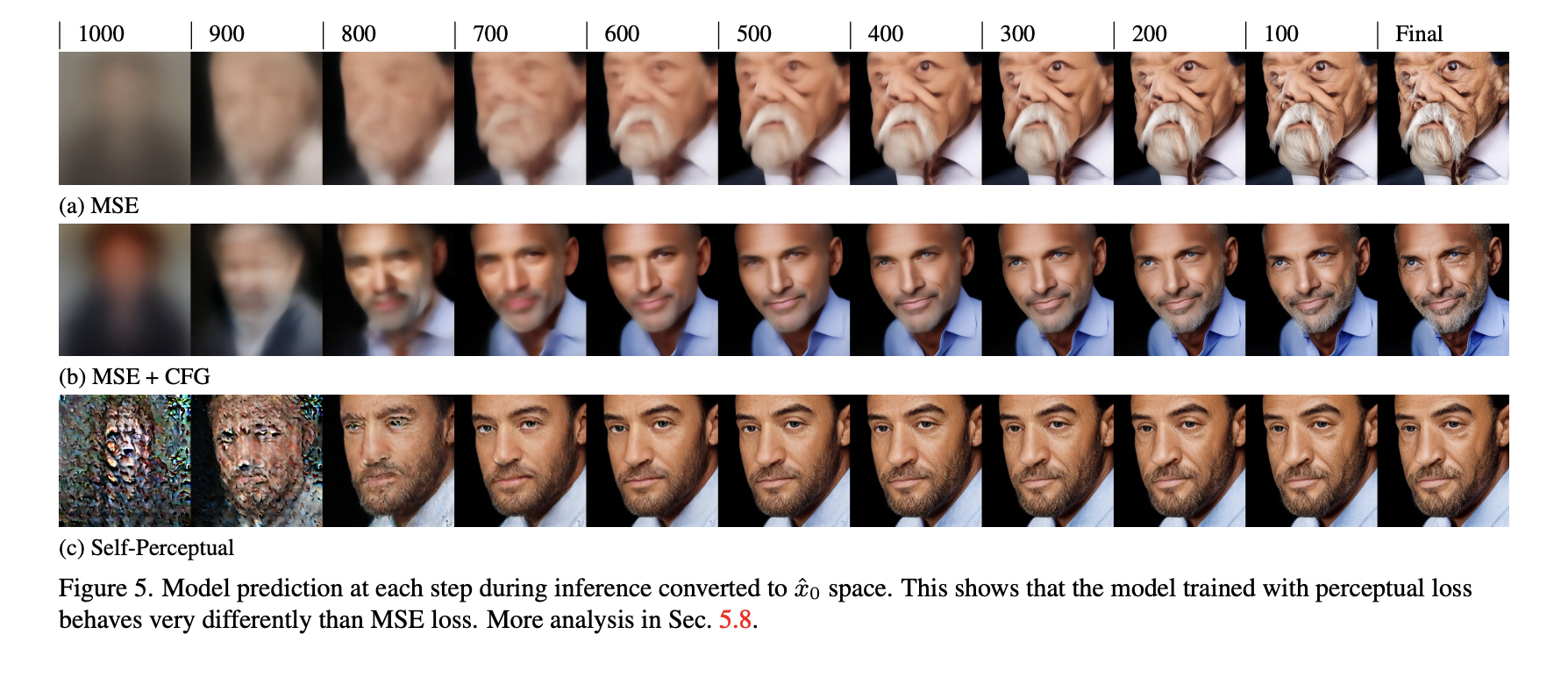
In their dispersion-type training, the research team employs a self-perceptual objective that leverages the model’s inherent perception network to induce immediate visual loss. By predicting the trajectory of a regular or chaotic divergent equation, the model transforms noise into a more structured and coherent image. This strategy strikes a balance between improving test quality and preserving sample diversity, a crucial aspect in applications like text-to-image generation, unlike previous techniques.
The adoption of the self-perceptual objective has proven to outperform traditional mean squared error objectives significantly, as indicated by statistical analyses measuring metrics like the Fréchet Inception Distance and Inception Score. This advancement has led to a notable enhancement in the visual quality and authenticity of the generated images. While the process still falls short of the classifier-free guidance in terms of overall sample quality, it circumvents the pitfalls of image overexposure by offering a more nuanced and sophisticated approach to image creation.
In essence, the study underscores the substantial progress made in propagation models concerning image generation. The integration of a self-perceptual objective during diffusion training has paved the way for producing highly realistic and top-notch images, opening up new avenues for the development of relational models. This innovative approach undoubtedly enhances the capabilities of these models across various applications, from artistic creation to complex machine vision tasks. The research not only sets the stage for further exploration but also holds the promise of significant advancements in diffusion model training, shaping the trajectory of future studies in this domain.