
LLM variations, serving as highly proficient language models employed for diverse programming assignments, have experienced a surge in utilization. Despite their impressive advancements, a noticeable gap persists between the capabilities of these models in dynamic experimental settings and the evolving requirements of real-world development contexts.
While conventional benchmarks for code generation evaluate the ability of LLMs to create new scripts from scratch, practical programming often involves leveraging existing, publicly accessible libraries. These libraries provide dependable solutions to a variety of challenges, contrasting the necessity of starting code development from the ground up.
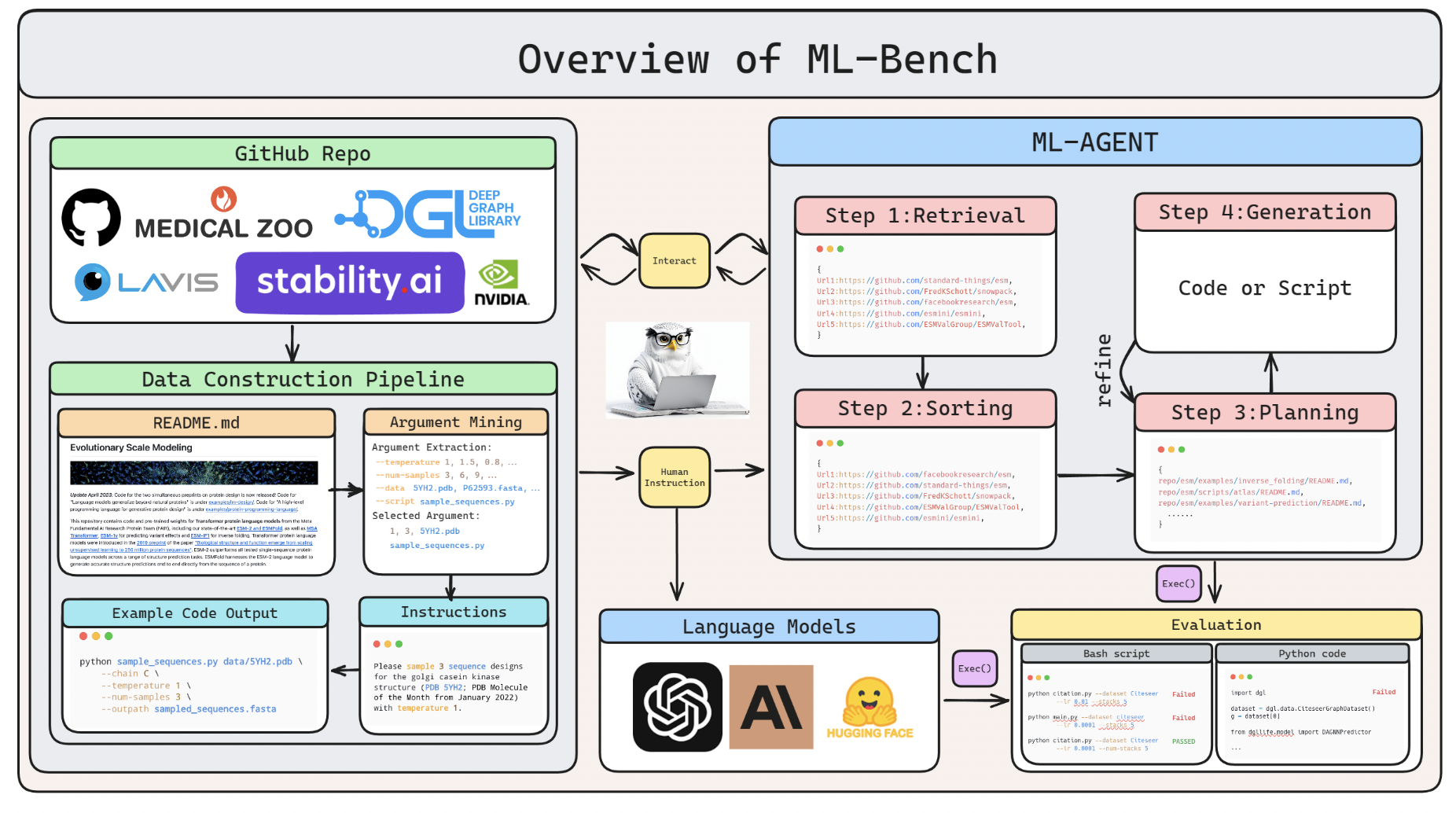
To conduct a comprehensive assessment of script LLMs, their performance should encompass more than just code generation; it should also involve executing code extracted from open-source libraries with accurate parameter utilization. This holistic evaluation can be facilitated through tools like ML-Chair, a thorough benchmark dataset collaboratively developed by Yale University, Nanjing University, and Peking University. ML-BENCH offers a high-caliber dataset comprising 9,444 cases, 130 tasks, and 14 prevalent devices learning GitHub repositories, enabling the evaluation of LLMs’ capacity to understand user instructions, navigate repositories, and produce executable code.
Researchers evaluate the performance of various LLMs such as GPT-3.5-16k, GPT-4, Claude 2, and CodeLlama in ML-BENCH scenarios using metrics like Pass@k and Parameter Hit Precision. The findings reveal that GPT-4 surpasses other LLMs significantly, despite accomplishing only 39.73% of the tasks. In contrast, CodeLlama falls behind, while other LLMs display deficiencies. These results indicate that LLMs have the potential to interpret extensive documentation in addition to coding tasks.
In response to the identified shortcomings, the researchers introduce ML-AGENT, an intelligent language agent crafted to address these limitations. ML-AGENT excels in comprehending human language and directives, generating efficient code, and executing intricate tasks, marking a notable progression in automated machine learning methodologies.
The introduction of ML-Bench and AI represents a significant stride forward in automated machine learning techniques, carrying implications for both academic research and professional applications.




