
In the realm of machine learning (ML) research at Meta, the issue of debugging at scale has prompted the creation of HawkEye, a robust toolkit tailored to tackle the intricacies of monitoring, observability, and debuggability. Given that ML-driven products form the cornerstone of Meta’s offerings, the intricate landscape of data distributions, multiple models, and ongoing A/B experiments presents a formidable obstacle. The core challenge revolves around swiftly pinpointing and remedying production issues to uphold the reliability of predictions and, by extension, the overall user experiences and revenue strategies.
Traditionally, addressing ML model and feature debugging at Meta necessitated specialized expertise and cross-functional coordination. Engineers often had to resort to shared notebooks and code for conducting root cause analyses, a process that demanded significant time and effort. HawkEye emerges as a game-changing solution, introducing a decision tree-based methodology that simplifies the debugging process. Unlike traditional approaches, HawkEye drastically reduces the time dedicated to resolving intricate production issues. Its inception heralds a paradigm shift, enabling both ML experts and non-specialists to handle problem triage with minimal coordination and support.
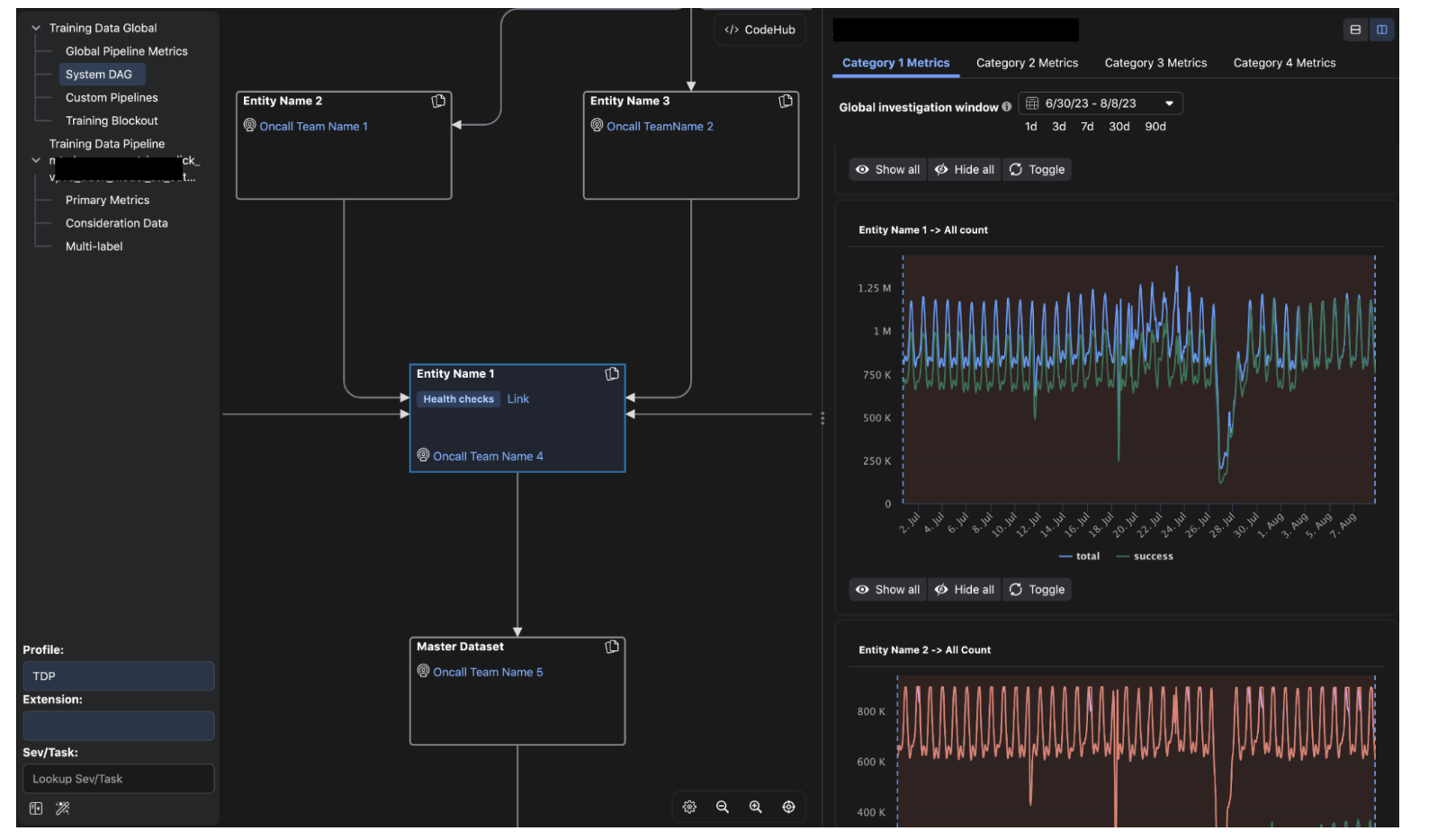
The operational debugging workflows of HawkEye are meticulously crafted to offer a methodical framework for identifying and rectifying anomalies in key performance metrics. By zeroing in on specific serving models, infrastructure variables, or traffic-related components, the toolkit effectively eradicates these anomalies. The decision tree-guided approach then isolates models exhibiting prediction deterioration, allowing on-call personnel to assess prediction quality across diverse experiments. HawkEye’s proficiency extends to pinpointing suspicious model snapshots, streamlining the mitigation process, and expediting issue resolution.
A standout feature of HawkEye lies in its capacity to attribute prediction anomalies to specific features, leveraging sophisticated model explainability and feature importance algorithms. By conducting real-time analyses of model inputs and outputs, correlations between time-aggregated feature distributions and prediction distributions can be computed. The outcome is a prioritized list of features accountable for prediction anomalies, equipping engineers with a potent tool to promptly address issues. This streamlined methodology enhances the efficiency of the triage process and markedly reduces the time span from issue identification to feature resolution, marking a significant leap forward in debugging practices.
In summary, HawkEye emerges as a pivotal asset in Meta’s quest to elevate the quality of ML-driven products. Its streamlined decision tree-based approach simplifies operational workflows and empowers a broader spectrum of users to adeptly navigate and triage complex issues. The extensibility features and collaborative endeavors within the community promise ongoing enhancements and adaptability to emerging hurdles. As delineated in the discourse, HawkEye plays a pivotal role in enhancing Meta’s debugging capabilities, ultimately contributing to the delivery of captivating user experiences and effective monetization strategies.




