
Artificial intelligence has witnessed notable progress with the evolution of large language models (LLMs). The utilization of techniques such as reinforcement learning from human feedback (RLHF) has significantly enhanced their performance across various tasks. However, a key challenge remains in generating original content solely based on human feedback.
A fundamental obstacle in advancing LLMs is the optimization of their learning process through human feedback. This feedback is acquired through a methodology where models receive prompts, generate responses, and human raters express their preferences. The objective is to fine-tune the models’ responses to better align with human preferences. Nonetheless, this approach necessitates numerous interactions, creating a bottleneck for swift model enhancement.
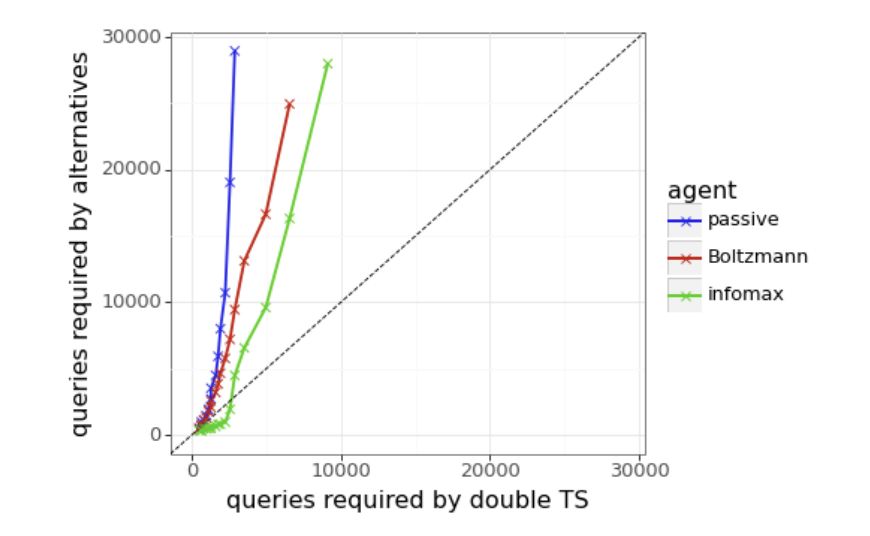
Present strategies for training LLMs involve passive exploration, where models generate responses based on predetermined prompts without actively striving to optimize learning from feedback. One such strategy involves the use of Thompson sampling, where queries are formulated based on uncertainty estimates provided by an epistemic neural network (ENN). The selection of an exploration scheme is crucial, with double Thompson sampling proving effective in generating high-quality queries. Other methods include Boltzmann Exploration and Infomax. While these techniques have been pivotal in the initial phases of LLM development, there is a need for efficiency optimization, as they often demand an impractical number of human interactions to yield significant improvements.
Researchers at Google Deepmind and Stanford University have introduced an innovative approach to active exploration, leveraging double Thompson sampling and ENN for query generation. This method empowers the model to actively pursue feedback that is most enlightening for its learning process, substantially reducing the required number of queries to achieve superior performance levels. The ENN offers uncertainty estimates that steer the exploration process, enabling the model to make well-informed decisions on which queries to present for feedback.
In the experimental setup, agents produce responses to 32 prompts, creating queries that are assessed by a preference simulator. The feedback is utilized to refine their reward models at the conclusion of each epoch. Agents navigate the response space by selecting the most informative pairs from a pool of 100 candidates, employing a multi-layer perceptron (MLP) architecture with two hidden layers of 128 units each or an ensemble of 10 MLPs for epistemic neural networks (ENN).
The results underscore the efficacy of double Thompson sampling (TS) compared to other exploration methods like Boltzmann exploration and infomax, particularly in leveraging uncertainty estimates for enhanced query selection. While Boltzmann exploration exhibits potential at lower temperatures, double TS consistently outperforms others by leveraging uncertainty estimates from the ENN reward model more effectively. This approach expedites the learning process and showcases the potential for efficient exploration to significantly reduce the volume of human feedback required, representing a substantial leap forward in LLM training.
In summary, this research demonstrates the potential of efficient exploration in overcoming the constraints of traditional training approaches. The team has paved the way for rapid and effective model improvement by harnessing advanced exploration algorithms and uncertainty estimates. This methodology holds the promise of expediting innovation in LLMs and underscores the significance of optimizing the learning process for the broader progression of artificial intelligence.
Check out the Paper.All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Gr oup.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
🎯 [FREE AI WEBINAR] ‘Actions in GPTs: Developer Tips, Tricks & Techniques’ (Feb 12, 2024)








