
In language model alignment, the efficiency of reinforcement learning from human feedback (RLHF) relies heavily on the quality of the underlying reward model. A critical aspect is ensuring the excellence of this reward model, as it significantly impacts the success of RLHF applications. The primary challenge lies in constructing a reward model that precisely mirrors human preferences, a crucial element in achieving optimal performance and alignment in language models.
Recent progress in large language models (LLMs) has been facilitated by aligning their behavior with human values. RLHF, a commonly used strategy, steers models towards desired outputs by defining a nuanced loss function that reflects subjective text quality. However, accurately capturing human preferences entails expensive data collection. The quality of preference models is contingent on factors such as the volume of feedback, the distribution of responses, and the precision of labels.
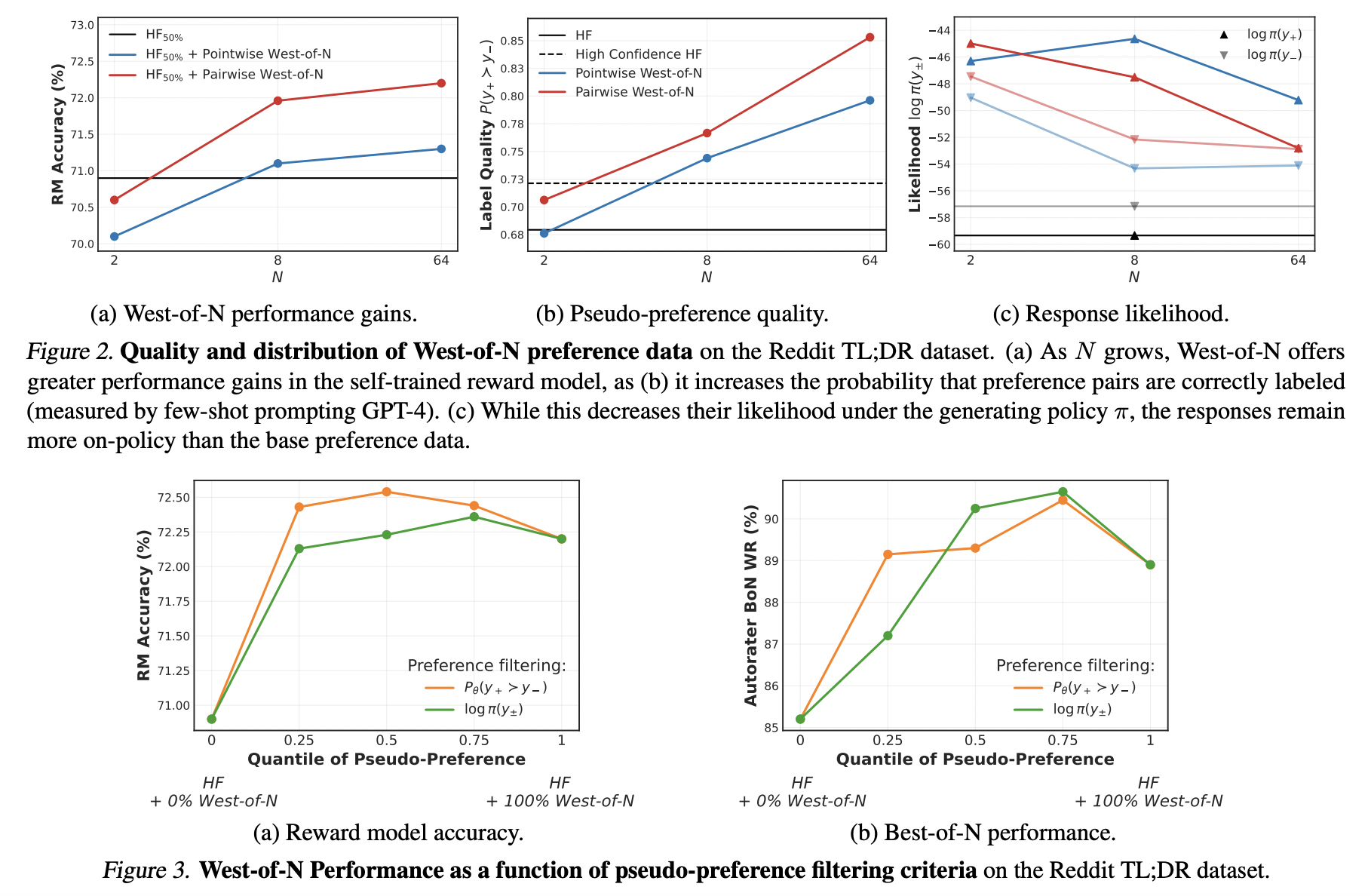
Researchers from ETH Zurich, Max Planck Institute for Intelligent Systems, Tubingen, and Google Research have introduced West-of-N: Synthetic Preference Generation for Enhanced Reward Modeling. This innovative approach aims to improve the quality of reward models by integrating synthetic preference data into the training dataset. Building upon the success of Best-of-N sampling strategies in language model training, they extend this methodology to reward model training. The proposed self-training technique generates preference pairs by selecting the best and worst candidates from response pools for specific queries.
The West-of-N method generates synthetic preference data by choosing the best and worst responses to a given query from the language model’s policy. Drawing inspiration from Best-of-N sampling strategies, this self-training approach significantly boosts reward model performance, akin to the impact of including a similar volume of human preference data. The methodology is delineated in Algorithm 1, which provides a theoretical assurance of accurate labeling for the generated preference pairs. Filtering procedures based on model confidence and response distribution further enhance the quality of the generated data.
The study assesses the efficacy of the West-of-N synthetic preference data generation method on the Reddit TL;DR summarization and Anthropic Helpful and Harmless dialogue datasets. The results demonstrate that West-of-N substantially enhances reward model performance, surpassing the benefits derived from additional human feedback data and outperforming other synthetic preference generation techniques like RLAIF and RLCD. West-of-N consistently enhances model accuracy, Best-of-N sampling, and RL-finetuning across various base preference types, underscoring its effectiveness in language model alignment.
In conclusion, researchers from Google Research and other esteemed institutions have proposed an impactful strategy, West-of-N, to elevate reward model (RM) performance in RLHF. Experimental findings underscore the method’s effectiveness across diverse initial preference data and datasets. The study underscores the potential of Best-of-N sampling and semi-supervised learning for preference modeling. Furthermore, it suggests exploring methods like noisy student training to enhance RM performance in conjunction with West-of-N.




