
Large-scale Language Models (LLMs) have demonstrated impressive capabilities in diverse natural language processing endeavors. However, their application to Information Retrieval (IR) tasks presents challenges due to the scarcity of IR-specific concepts in natural language. To address this issue, the concept of instruction tuning has emerged as a crucial method for enhancing LLMs’ capabilities and control. While instruction fine-tuned LLMs have shown proficiency in adapting to new tasks, there remains a gap in their utilization for IR tasks.
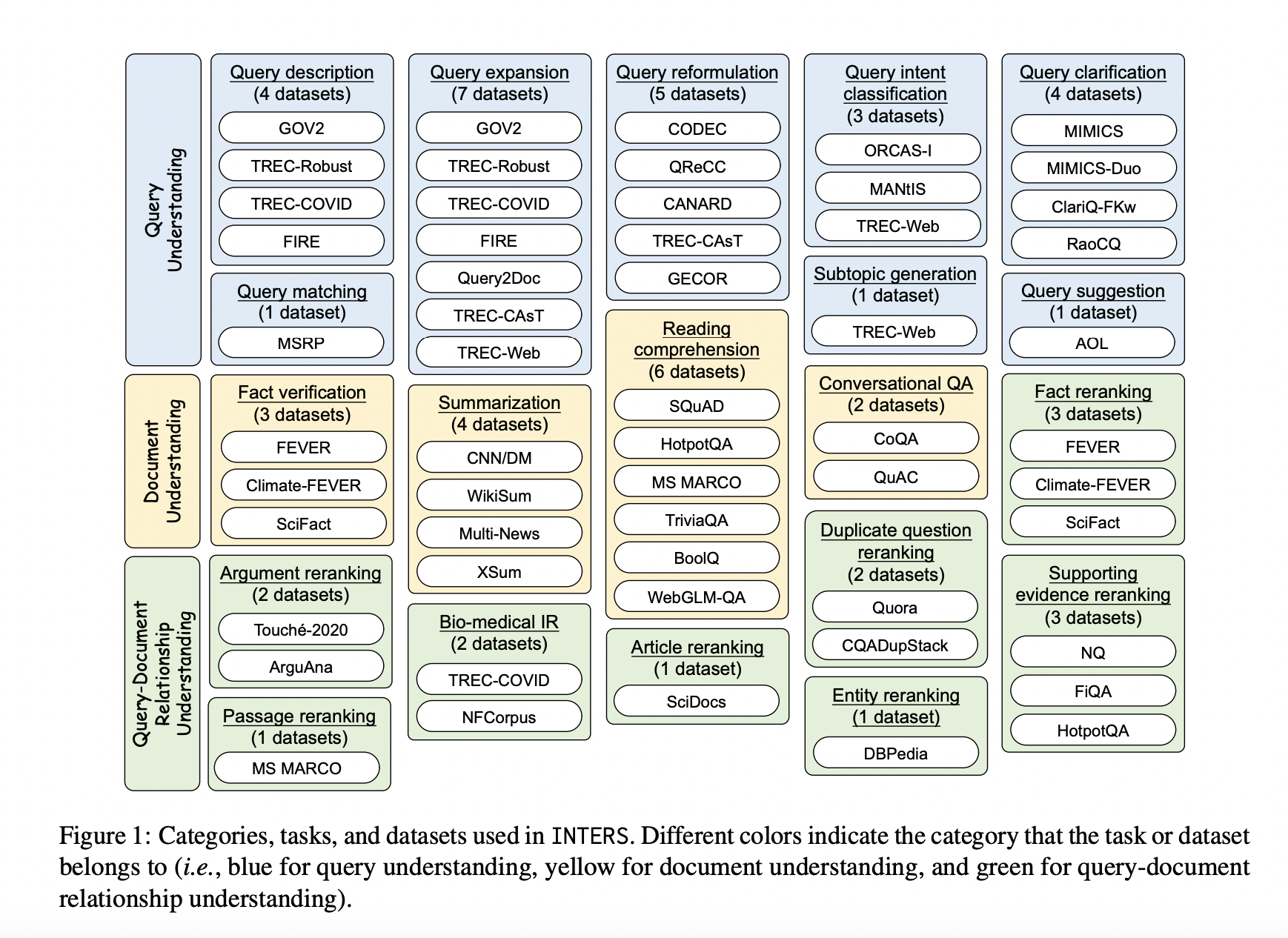
In response to this challenge, this study introduces a new dataset called INTERS (INstruction Tuning datasEt foR Search), meticulously designed to augment the search capabilities of LLMs. This dataset focuses on three essential aspects crucial to search-related tasks: query understanding, document comprehension, and the intricate relationship between queries and documents. INTERS is a comprehensive resource comprising 43 datasets encompassing 20 distinct search-related tasks.
Instruction Tuning involves fine-tuning pre-trained LLMs on formatted instances represented in natural language. This approach not only enhances performance on directly trained tasks but also enables LLMs to generalize to new, unseen tasks. In the context of search tasks, which differ from typical NLP tasks, the emphasis lies on queries and documents, leading to the categorization of tasks into query understanding, document understanding, and query-document relationship understanding.
Tasks & Datasets:
Creating a comprehensive instruction-tuning dataset for a wide array of tasks is resource-intensive. To mitigate this challenge, existing datasets from the IR research community are transformed into an instructional format. Categories include:
- Query Understanding: Covering query description, expansion, reformulation, intent classification, clarification, matching, subtopic generation, and suggestion.
- Document Understanding: Encompassing fact verification, summarization, reading comprehension, and conversational question-answering.
- Query-Document Relationship Understanding: Primarily focusing on the document reranking task.
The development of INTERS involves a meticulous process of manually crafting task descriptions and templates and aligning data samples with these templates. This meticulous approach underscores the commitment to creating a comprehensive and instructive dataset.
For evaluation purposes, four LLMs of varying sizes are utilized: Falcon-RW-1B, Minima-2-3B, Mistral-7B, and LLaMA-2-7B. Through in-domain evaluation, where all tasks and datasets are exposed during training, the efficacy of instruction tuning on search tasks is confirmed. Furthermore, the authors explore the generalizability of fine-tuned models to new, unseen tasks, examining Group-level, Task-level, and Dataset-level generalizability to provide insights into the adaptability of instruction-tuned LLMs.
Various experiments are conducted to assess the impact of different settings within INTERS. Notably, the removal of task descriptions from the dataset significantly influences model performance, underscoring the importance of clear task comprehension.
Templates and guiding models play a crucial role in task comprehension within INTERS. Ablation experiments demonstrate that the use of instructional templates substantially enhances model performance.
Given INTERS’s mix of zero-shot and few-shot examples, evaluating few-shot performance is essential. Testing datasets within models’ input length limits showcases the dataset’s effectiveness in facilitating few-shot learning.
The study delves into the exploration of training data quantity, with experiments indicating that increasing the volume of instructional data generally improves model performance, albeit with varying sensitivity across tasks.
In conclusion, this research presents an investigation of instruction tuning for LLMs applied to search tasks, culminating in the development of the INTERS dataset. The dataset proves effective in consistently enhancing LLMs’ performance across different scenarios. The study sheds light on critical aspects such as the structure of instructions, the impact of few-shot learning, and the significance of data volumes in instruction tuning. The aim is to inspire further research in the realm of LLMs, particularly in their integration into IR tasks, fostering continuous optimization of instruction-based methods to boost model performance.




