
Causal reasoning, a fundamental aspect of human intelligence, involves discerning the cause-effect relationship. It plays a pivotal role in scientific reasoning and decision-making, contributing significantly to enhanced problem-solving skills across various domains.
While previous studies have delved into the causal reasoning prowess of Large Language Models (LLMs), they often fell short in fully leveraging the models’ potential in this realm. LLMs sometimes rely on superficial textual patterns rather than a deep understanding of causal relationships to answer causal queries accurately. To address this, a collaborative team of researchers from MPI for Intelligent Systems, Tübingen, ETH Zürich, IIT Kharagpur, University of Hong Kong, and the University of Washington introduced the CLADDER dataset. This dataset aims to evaluate formal causal reasoning in LLMs through symbolic questions and corresponding ground truth answers.
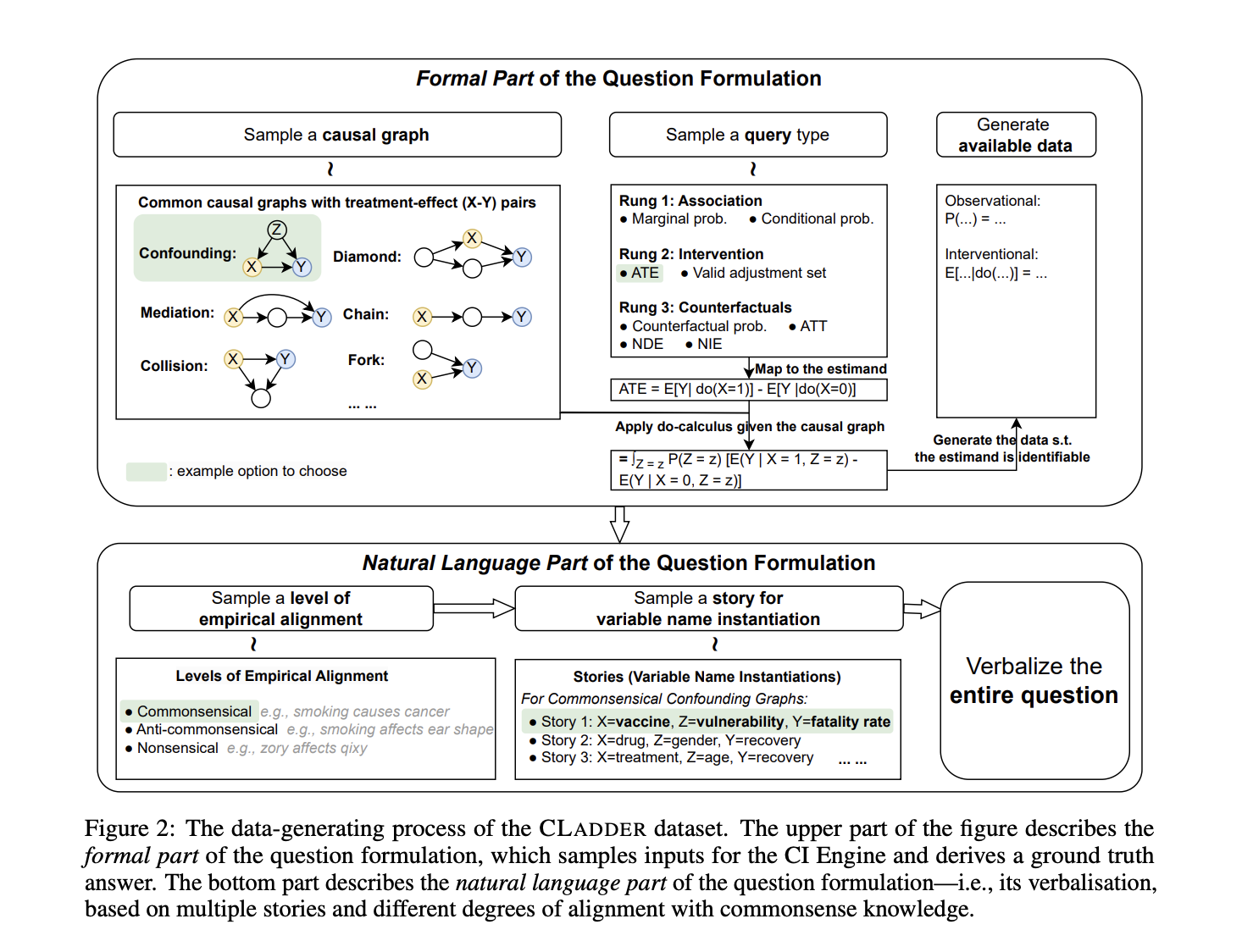
The CLADDER dataset comprises over 10,000 causal questions spanning a wide range of inquiries across the three tiers of the Ladder of Causation – associational, interventional, and counterfactual. The dataset includes diverse causal graphs that necessitate varying levels of causal inference capabilities. To facilitate a comprehensive analysis of LLMs, the researchers provided detailed sequential explanations alongside the questions and answers, transforming them into narrative form. Additionally, step-by-step explanations were crafted to elucidate intermediate reasoning processes for improved model performance.
To maintain dataset integrity and optimize inferential efficiency, the team limited the dataset size to 10K while ensuring a balanced distribution across graph structures, query types, narratives, and ground-truth responses. Notably, CLADDER incurred zero human annotation costs and underwent meticulous scrutiny to rectify grammatical inaccuracies.
Furthermore, the researchers devised CausalCOT, a strategic prompting mechanism that simplifies causal reasoning tasks by decomposing complex problems into manageable steps. Leveraging the GPT-4 model, CausalCOT guides the model in extracting causal queries, graphs, and relevant data from the questions to derive accurate inferences.
In evaluating model performances on causal reasoning tasks, including GPT, LLaMa, and Alpaca, findings revealed challenges faced by these models in tackling the CLADDER dataset. Notably, GPT-4 achieved an accuracy of 64.28%, while CausalCOT surpassed this with a 66.64% accuracy rate. CausalCOT exhibited enhanced reasoning abilities across various scenarios, particularly excelling in anti-commonsensical and nonsensical data, indicating its efficacy in handling unseen data.
While acknowledging certain limitations in their study, such as the dataset’s coverage of only a subset of common queries across all three tiers, the researchers emphasized the need for future endeavors to expand the scope to encompass a broader array of causal inquiries. They also underscored the importance of evaluating LLM capabilities in semi-realistic settings for more robust assessments. Nevertheless, this research introduces a rigorous benchmark for evaluating LLMs’ causal reasoning capabilities, marking a significant stride in overcoming previous limitations and enhancing causal reasoning proficiency in LLMs.




