Large Language Models (LLMs) have demonstrated significant capabilities across a range of natural language tasks, including text summarization, question answering, and code generation, among others. They have emerged as a potent solution for numerous real-world challenges. However, one area where these models face challenges is in goal-directed conversations, where they need to achieve specific objectives through dialogue, such as serving as an efficient travel agent to offer personalized travel plans. In such scenarios, they often provide verbose and impersonal responses.
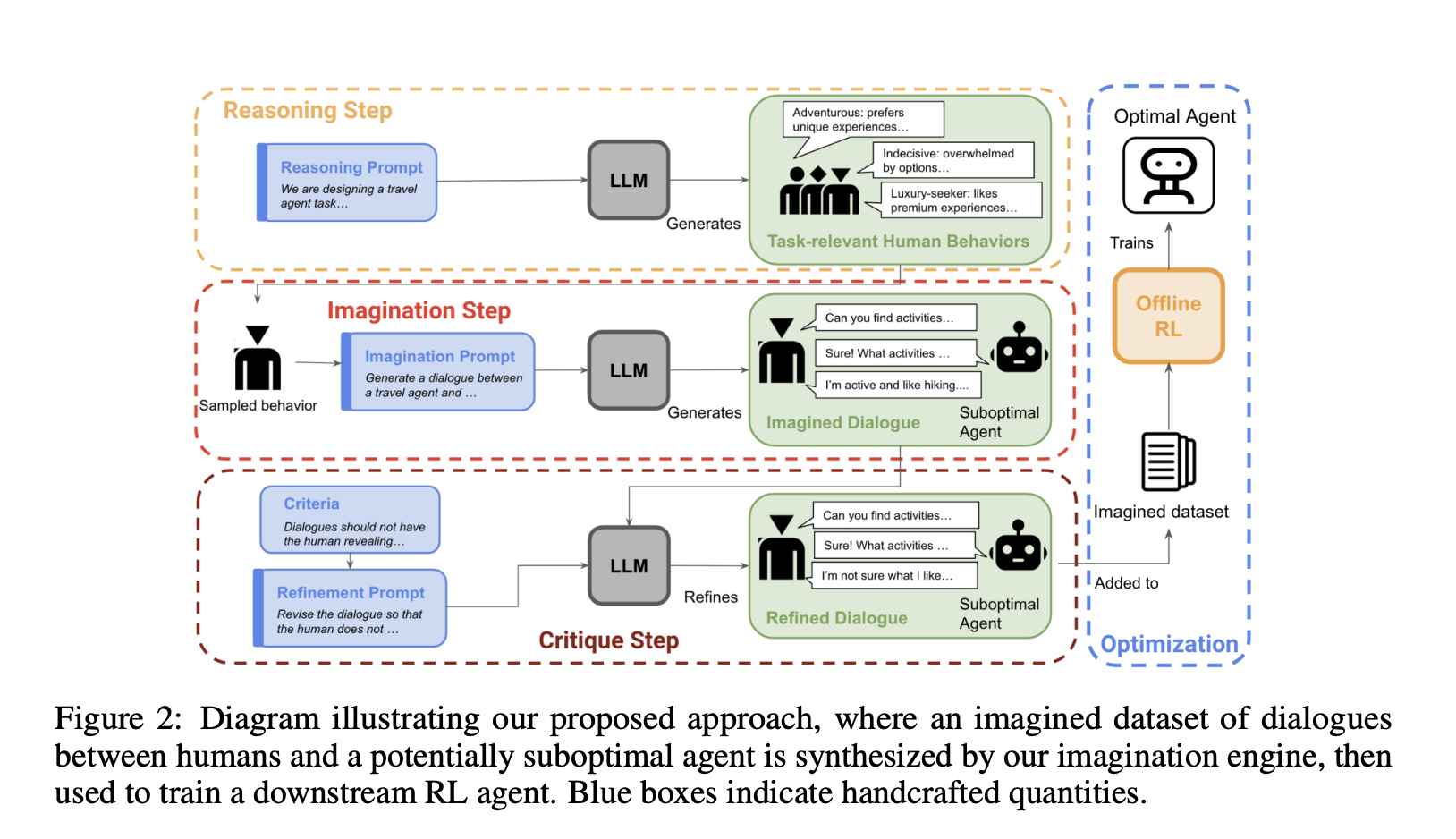
Models that undergo supervised fine-tuning or single-step reinforcement learning (RL) commonly encounter difficulties in these tasks as they are not specifically optimized for achieving conversational goals through multiple interactions. Additionally, they struggle with handling uncertainties within such dialogues. In a recent study, researchers from UC Berkeley have proposed a new approach to adapt LLMs with RL for goal-directed conversations. Their innovations include an optimized zero-shot algorithm and a unique system named the “imagination engine (IE)” designed to generate diverse and task-relevant queries for training downstream agents.
While the IE alone may not be sufficient to create effective agents, the researchers leverage an LLM to fabricate potential scenarios. To enhance an agent’s efficacy in accomplishing desired outcomes, multi-step reinforcement learning becomes crucial for determining the optimal strategy. A key modification introduced by the researchers involves utilizing offline value-based RL instead of on-policy samples to learn a policy from the synthetic data itself.
To evaluate the efficacy of their approach, the researchers compared the performance of a GPT agent with that of IE+RL using human evaluators. They examined two goal-directed conversations centered around real-world problems. The researchers employed the GPT-3.5 model within the IE for generating synthetic data and a relatively compact decoder-only GPT-2 model as the downstream agent. This pragmatic approach minimizes computational expenses, as it necessitates a cutting-edge model solely for data generation.
Their experiments revealed that the proposed agent consistently outperformed the GPT model across various metrics while maintaining the natural flow of the dialogue. Qualitatively, the IE+RL agent excelled by posing straightforward and contextually relevant questions, displaying intelligent sequencing based on previous interactions. A simulation comparison of the two agents indicated that although both performed comparably, the IE+RL agent surpassed the GPT agent, particularly in qualitative assessments.
In summary, the authors of this research paper have introduced a methodology to enhance the performance of LLMs in goal-directed conversations. By leveraging an imagination engine to generate diverse, task-specific, and realistic synthetic data for training dialogue agents, they have demonstrated significant improvements over conventional approaches. Their offline approach offers computational advantages, paving the way for future enhancements in this domain. The researchers envision further automation of this process to enhance zero-shot dialogue agents’ performance and elevate interactions with AI systems.