
The feature performance of the Low-rank Adaptation (LoRA) method has been enhanced by a team of Nvidia researchers through a method known as Tied-LoRA. The primary objective of this approach is to achieve an optimal balance between performance and adaptive parameters by leveraging weight tying and selective training techniques. Through their experiments on diverse tasks and fundamental language models, the researchers have identified trade-offs between effectiveness and performance.
LoRA, a method that diminishes adaptive parameters via low-rank structure approximations, represents a recent advancement in parameter-efficient fine-tuning strategies. AdaLoRA, an extension of LoRA, integrates converter tuning with robust rank adjustment. VeRA, introduced by Kopiczko, reduces parameters by employing adaptive scaling vectors and freezing matrices. QLoRA, aimed at obtaining memory-efficient LoRA, utilizes quantized base designs. The incorporation of fat tying to low-rank weight matrices in this study further enhances feature effectiveness.
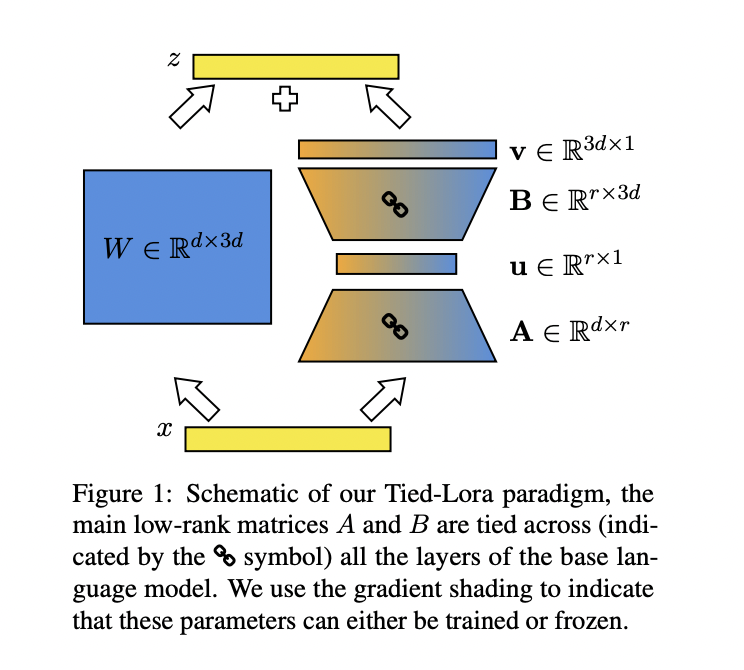
Tied-LoRA stands out as an innovative approach that combines weight tying and meticulous training to enhance the parameter efficiency of LoRA, addressing the computational burden of fine-tuning Large Language Models (LLMs) for downstream tasks. Through systematic experimentation across various studies and basic language models, the researchers explore different parameter training/freezing and weight-tying configurations. Compared to the conventional LoRA method, a specific Tied-LoRA setting is identified, achieving comparable performance while utilizing only 13% of the parameters.
By integrating fat tying with precise training, the Tied-LoRA method boosts the factor efficiency of the LoRA technique. This is achieved by reducing the number of adaptive parameters through weight tying to low-rank matrices in LoRA and sharing effects across layers in the underlying language model. Various combinations of factor training/freezing and weight tying are investigated to strike the optimal balance between performance and adaptive parameters. The proposed Tied-LoRA setups are evaluated across a range of tasks, demonstrating their effectiveness across datasets, including scientific reasoning and translation tasks.
Experiments involving diverse tasks and two fundamental language models reveal trade-offs between efficiency and performance across various Tied-LoRA configurations. Among these configurations, vBuA emerges as a top performer, exhibiting superior effectiveness while reducing parameters by 87%. Assessments on tasks such as summarization, mathematical logic, and industrial problem-solving highlight Tied-LoRA’s ability to significantly enhance parameter efficiency while maintaining competitive performance.
Through experiments on a variety of tasks, it is evident that the Tied-LoRA model leverages weight tying and meticulous training to enhance the feature performance of the LoRA process. The results suggest that Tied-LoRA could potentially replace tools in industrial question answering, commonsense natural language inference, and summarization tasks. Moreover, by utilizing only 13% of the parameters required by the standard LoRA method, it delivers superior feature effectiveness without compromising performance. Discussions on limitations and comparisons with alternative factor performance methods are essential for identifying potential areas for further exploration.




