
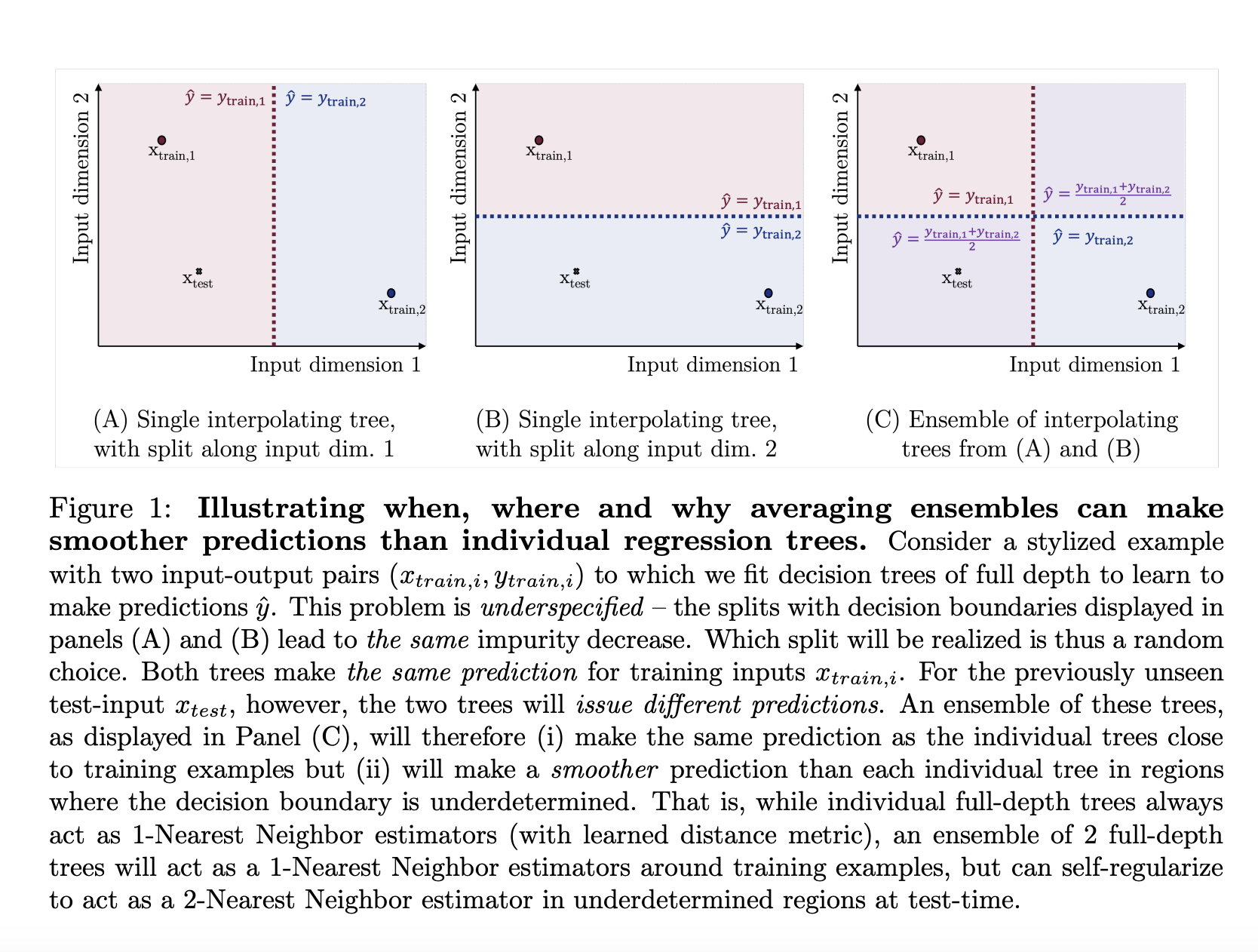
In the realm of machine learning, the efficacy of tree ensembles, such as random forests, has been widely recognized for quite some time. These ensembles amalgamate the predictive capabilities of multiple decision trees, distinguishing themselves with exceptional accuracy across diverse applications. Researchers at the University of Cambridge delve into the intricacies behind this success, offering a nuanced perspective that surpasses conventional explanations centered on variance reduction.
This study likens tree ensembles to adaptive smoothers, shedding light on their capacity to self-regulate and fine-tune predictions based on the complexity of the data. This adaptability plays a pivotal role in their performance, empowering them to navigate the nuances of data in ways that individual trees cannot. The ensemble’s predictive precision is elevated by adjusting its smoothing mechanism according to the resemblance between test inputs and training data.
At the heart of the ensemble’s methodology lies the incorporation of randomness in tree construction, serving as a form of regularization. This randomness is not haphazard but a deliberate element that bolsters the ensemble’s resilience. Ensembles introduce diversity in their predictions by injecting variability in feature and sample selection, mitigating the risk of overfitting and enhancing the model’s generalizability.
The empirical analysis outlined in the research underscores the practical implications of these theoretical insights. The researchers elaborate on how tree ensembles substantially diminish prediction variance through their adaptive smoothing approach. This is empirically substantiated through comparisons with individual decision trees, revealing a significant enhancement in predictive performance by ensembles. Noteworthy is the ensemble’s ability to smooth predictions and adeptly handle data noise, amplifying their dependability and accuracy.
Delving deeper into performance and outcomes, the study presents compelling evidence of the ensemble’s superior efficacy through experiments. Across various datasets, ensembles consistently demonstrate lower error rates than individual trees. This superiority is quantitatively validated using mean squared error (MSE) metrics, where ensembles outperform single trees by a considerable margin. The study also underscores the ensemble’s capability to calibrate its smoothing level in response to the testing environment, a flexibility that fortifies its robustness.
What distinguishes this study is its empirical discoveries and contribution to the conceptual comprehension of tree ensembles. By framing ensembles as adaptive smoothers, the researchers from the University of Cambridge offer a fresh perspective on these potent machine-learning tools. This viewpoint not only elucidates the internal mechanisms of ensembles but also unveils new avenues for refining their design and deployment.
This research delves into the effectiveness of tree ensembles in machine learning, drawing on both theoretical frameworks and empirical evidence. The perspective of adaptive smoothing provides a compelling rationale for the success of ensembles, underscoring their ability to self-regulate and refine predictions in ways that individual trees cannot. The incorporation of randomness as a regularization technique further underscores the sophistication of ensembles, bolstering their predictive prowess. Through a meticulous analysis, the study not only reaffirms the value of tree ensembles but also enriches our comprehension of their operational intricacies, paving the way for future advancements in the domain.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….

Muhammad Athar Ganaie, a consulting intern at MarktechPost, advocates for Efficient Deep Learning, focusing on Sparse Training. Pursuing an M.Sc. in Electrical Engineering with a specialization in Software Engineering, he merges advanced technical expertise with practical applications. His current research revolves around “Improving Efficiency in Deep Reinforcement Learning,” showcasing his dedication to enhancing AI capabilities. Athar’s work converges at the intersection of “Sparse Training in DNN’s” and “Deep Reinforcement Learning”.
🐝 Join the Fastest Growing AI Research Newsletter Read by Researchers from Google + NVIDIA + Meta + Stanford + MIT + Microsoft and many others…








