For all the revolutionary and disruptive capabilities associated with the emergence of artificial intelligence, the Achilles’ heel of generative AI lies in its inclination to fabricate information.
The propensity of Large Language Models (LLMs) to engage in “hallucinations” poses various risks, laying the groundwork for the dissemination of misinformation. The realm of Natural Language Processing (NLP) can be precarious, particularly when distinguishing between human-generated and AI-generated content becomes challenging.
To address this issue, Huggingface, self-proclaimed as the world’s largest Open Source AI community, has introduced the Hallucinations Leaderboard. This innovative ranking system is dedicated to assessing open source LLMs and their proclivity for generating hallucinatory content by subjecting them to a series of specialized benchmarks tailored for contextual learning.
The primary goal of this initiative is to assist researchers and engineers in pinpointing the most dependable models and potentially steering the advancement of LLMs towards more precise and faithful language production, as explained by the developers of the leaderboard.
The spectrum of hallucinations in LLMs can be categorized into two main types: factual and faithful. Factual hallucinations occur when the generated content contradicts verifiable real-world facts. For instance, an instance of this discrepancy could be a model erroneously stating that Bitcoin possesses 100 million tokens instead of the actual 23 million. On the other hand, faithful hallucinations arise when the generated content strays from the user’s explicit instructions or the established context, potentially introducing inaccuracies in crucial domains such as news summarization or historical analysis. In such cases, the model fabricates information because it deems it the most logical course based on its prompt.
To evaluate the performance of LLMs, the leaderboard leverages EleutherAI’s Language Model Evaluation Harness to conduct comprehensive zero-shot and few-shot evaluations across various tasks designed to assess the model’s behavior. Each test yields a score based on the LLM’s performance, and these scores are then averaged to enable a holistic comparison of each model’s overall performance across all tests.
So, which LLM architecture emerges as the most reliable among the cohort?
Initial findings from the Hallucinations Leaderboard suggest that models demonstrating fewer hallucinations—and consequently ranking higher—include Meow (Based on Solar), Stability AI’s Stable Beluga, and Meta’s LlaMA-2. However, certain models based on a common foundation (such as those rooted in Mistral LLMs) tend to outperform their counterparts in specific tests, a factor that users must consider based on their specific testing requirements.
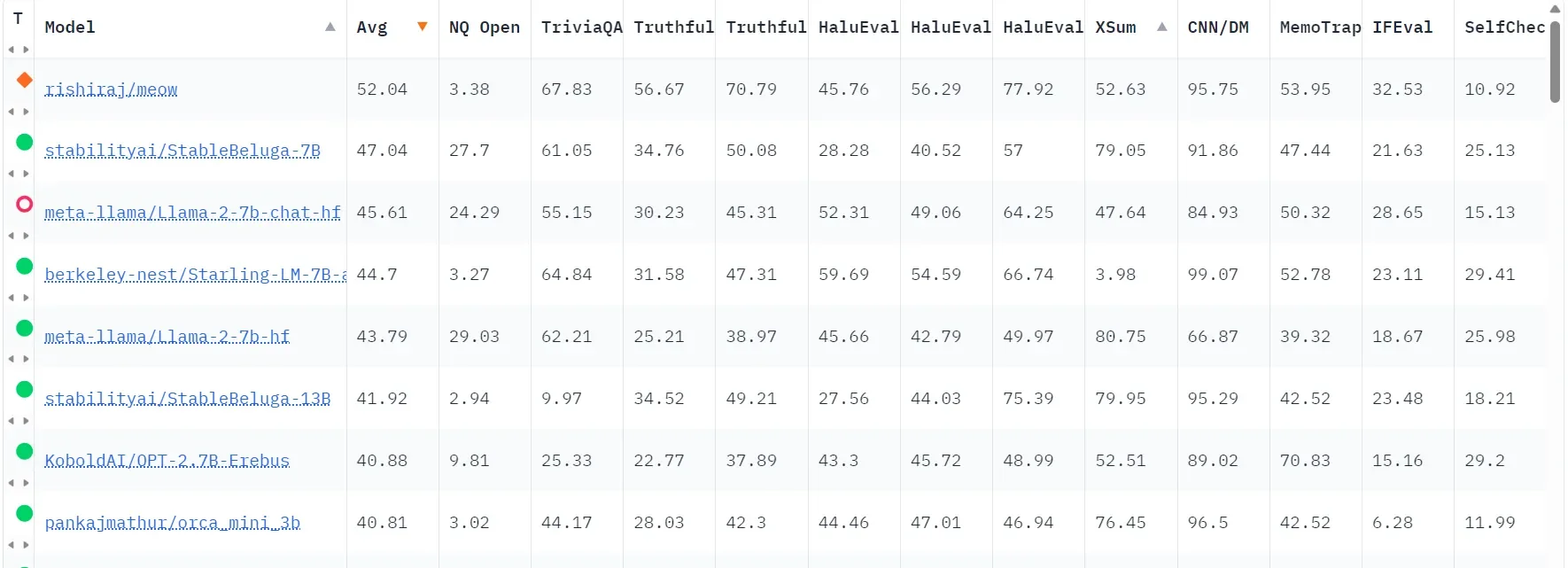 Image: Hugging Face
Image: Hugging Face
On the Hallucinations Leaderboard, a higher average score for a model signifies a lower tendency to hallucinate, indicating greater accuracy and reliability in generating content that aligns with factual information and conforms to the user’s input or the provided context.
Nevertheless, it is essential to recognize that models excelling in some tasks may fall short in others. Therefore, the ranking is established on an average performance across all benchmarks, encompassing diverse areas such as summarization, fact-checking, reading comprehension, and self-consistency, among others.
Dr. Pasquale Minervini, the mastermind behind the Hallucinations Leaderboard, was unavailable for immediate comment when contacted by Decrypt.
It is pertinent to acknowledge that while the Hallucinations Leaderboard offers a thorough evaluation of open-source models, closed-source models have yet to undergo similar rigorous testing. However, due to the testing protocols and proprietary constraints of commercial models, it appears unlikely that Hallucinations Leaderboard scoring will extend to these models.