
The field of Natural Language Processing (NLP) is presently experiencing a notable transformation, primarily driven by the rise of Large Language Models (LLMs) like the GPT series. These models are reshaping performance standards across a range of linguistic tasks. Autoregressive pretraining stands out as a crucial element contributing to this significant advancement. This technique involves training models to predict the most likely tokens in a sequence, enabling them to understand the intricate relationship between syntax and semantics, thus enhancing their ability to comprehend language akin to human cognition. Autoregressive pretraining has not only revolutionized NLP but has also made significant strides in the realm of computer vision.
While autoregressive pretraining initially showed promise in computer vision, recent developments have shifted the focus towards BERT-style pretraining. This transition gains significance from findings indicating comparable performance between autoregressive and BERT-style pretraining, as evidenced by initial results from iGPT. However, due to its superior effectiveness in visual representation learning, the preference has leaned towards BERT-style pretraining. Recent studies suggest that an effective method for visual representation learning could be as simple as predicting randomly masked pixel values.
A recent study by research teams at Johns Hopkins University and UC Santa Cruz has reexamined the potential of autoregressive pretraining in cultivating proficient vision learners on a broader scale. Their approach involves two key modifications. Firstly, they utilize the BEiT model to tokenize images into semantic tokens, acknowledging the noise and redundancy inherent in images. This adjustment shifts the focus of autoregressive prediction from individual pixels to semantic tokens, enabling a nuanced understanding of relationships between different regions within an image. Secondly, they introduce a discriminative decoder alongside the generative decoder to predict subsequent semantic tokens in an autoregressive fashion.
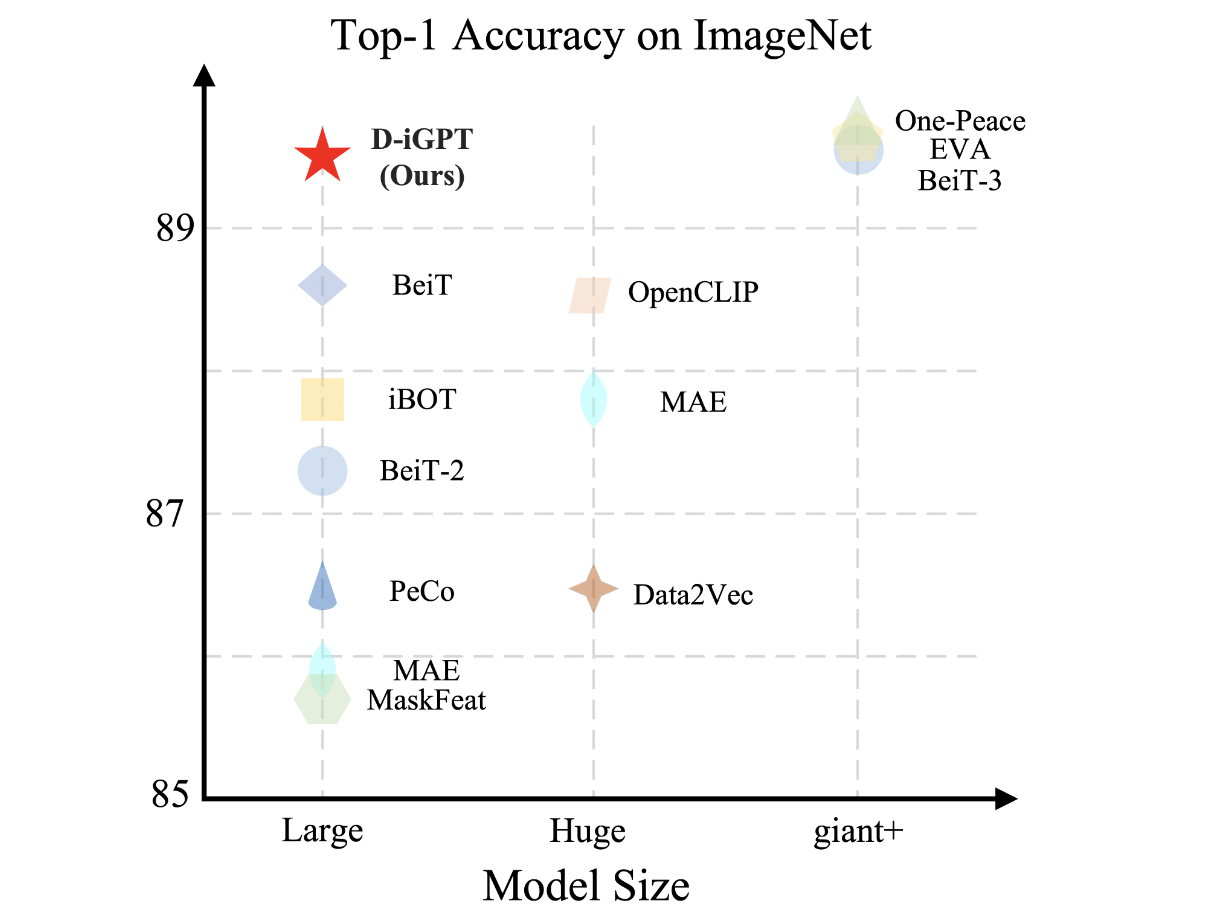
The discriminative decoder is responsible for predicting semantic tokens corresponding to observed pixels. Models trained discriminatively, such as CLIP, excel at generating semantic visual tokens that align effectively with this pretraining framework. This refined approach, known as D-iGPT, has shown remarkable efficiency through thorough evaluations across various datasets and tasks. Their base-size model surpasses the previous state-of-the-art by 0.6%, achieving an impressive 86.2% top-1 classification accuracy on the ImageNet-1K dataset.
Moreover, their large-scale model achieves an outstanding 89.5% top-1 classification accuracy using 36 million publicly available datasets. D-iGPT demonstrates performance comparable to earlier state-of-the-art models trained on public datasets, despite utilizing significantly less training data and a smaller model size. The research team also conducted an analysis of D-iGPT on semantic segmentation tasks using the same pretraining and fine-tuning dataset, revealing superior performance compared to its MAE counterparts.




